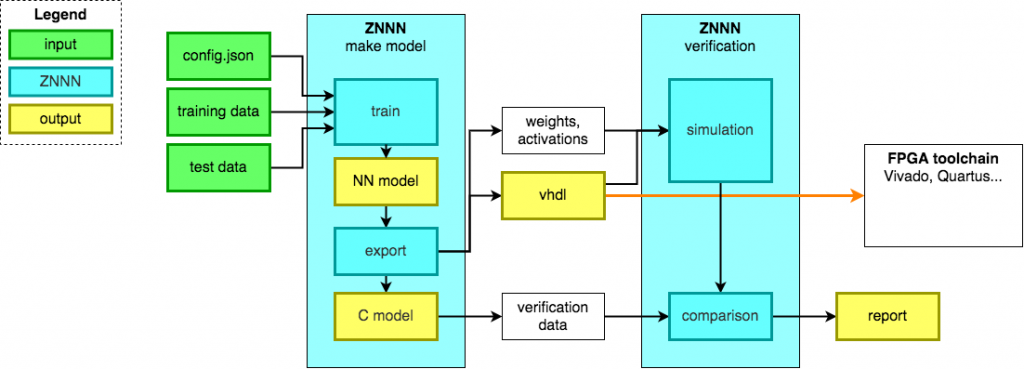
ZNNN the Framework to Port Neural Networks to FPGA
BY TOBIAS WELTI AND HANS-JOACHIM GELKE Due to their hardware architecture, Field Programmable Gate Arrays (FPGAs) are optimally suited for the execution of machine learning algorithms. These algorithms require the calculation of millions or even billions of multiplications for each input. To successfully accelerate a neural network, parallel execution of multiplication is the key. The […]