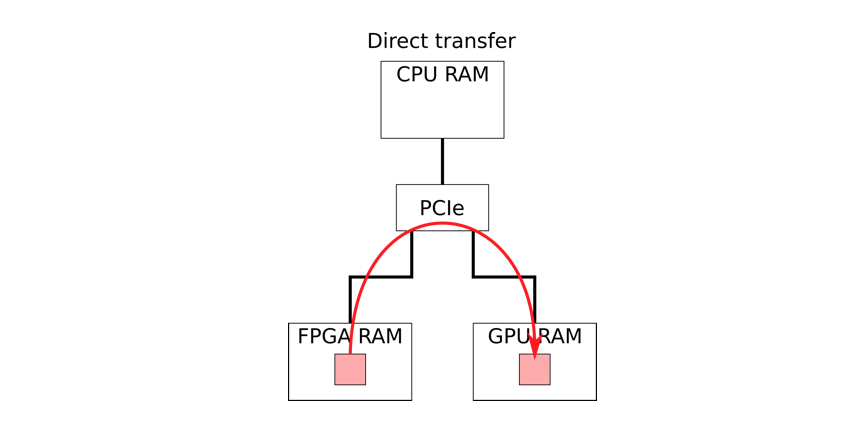
Direct communication between FPGA and GPU using Frame Based DMA (FDMA)
By Philipp Huber, Hans-Joachim Gelke, Matthias Rosenthal GPUs with their immense parallelization are best fitted for real-time video and signal processing. However, in a real-time system, the direct high-speed interface to the signal sources, such as cameras or sensors, is often missing. For this task, field programmable gate arrays (FPGA) are ideal for capturing and […]