 In business, especially marketing, it is often necessary to perform customer selection. The typical task involves defining a set of customers for upselling, cross-selling or retention actions. Traditionally, the selection criterion is the positive response probability. While this identifies customers who are the most likely to respond, it does not necessarily provide the optimal solution from which the business profits the most.
In business, especially marketing, it is often necessary to perform customer selection. The typical task involves defining a set of customers for upselling, cross-selling or retention actions. Traditionally, the selection criterion is the positive response probability. While this identifies customers who are the most likely to respond, it does not necessarily provide the optimal solution from which the business profits the most.
Over the last years, the concept of customer lifetime value (CLV) has attracted increasing attention. It suggests rating and selecting the customers by the present value of all future revenues that are attributed to their relationship. Hence, the focus lies on customer quality, rather than customer quantity. While this may sound logical, it provides a huge analytical challenge: the CLV is driven by the future behavior of a customer, which of course is not known in advance. Predictive analytics can and needs to be used for modeling customer dynamics, and often big data is involved.
Novel Semi-Markov Model Approach
Members of the Datalab at ZHAW developed a scalable framework based on Semi-Markov models (SMM) which can be used for structured CLV estimation. The basis of this approach lies in partitioning the customers into a space with several (usually 2-20) distinct states. This allows for differentiated lifetime models, transition probabilities and revenue distributions. We illustrate the concept with an example of a CLV system implemented for a telecommunication company in Switzerland. The states are as follows:
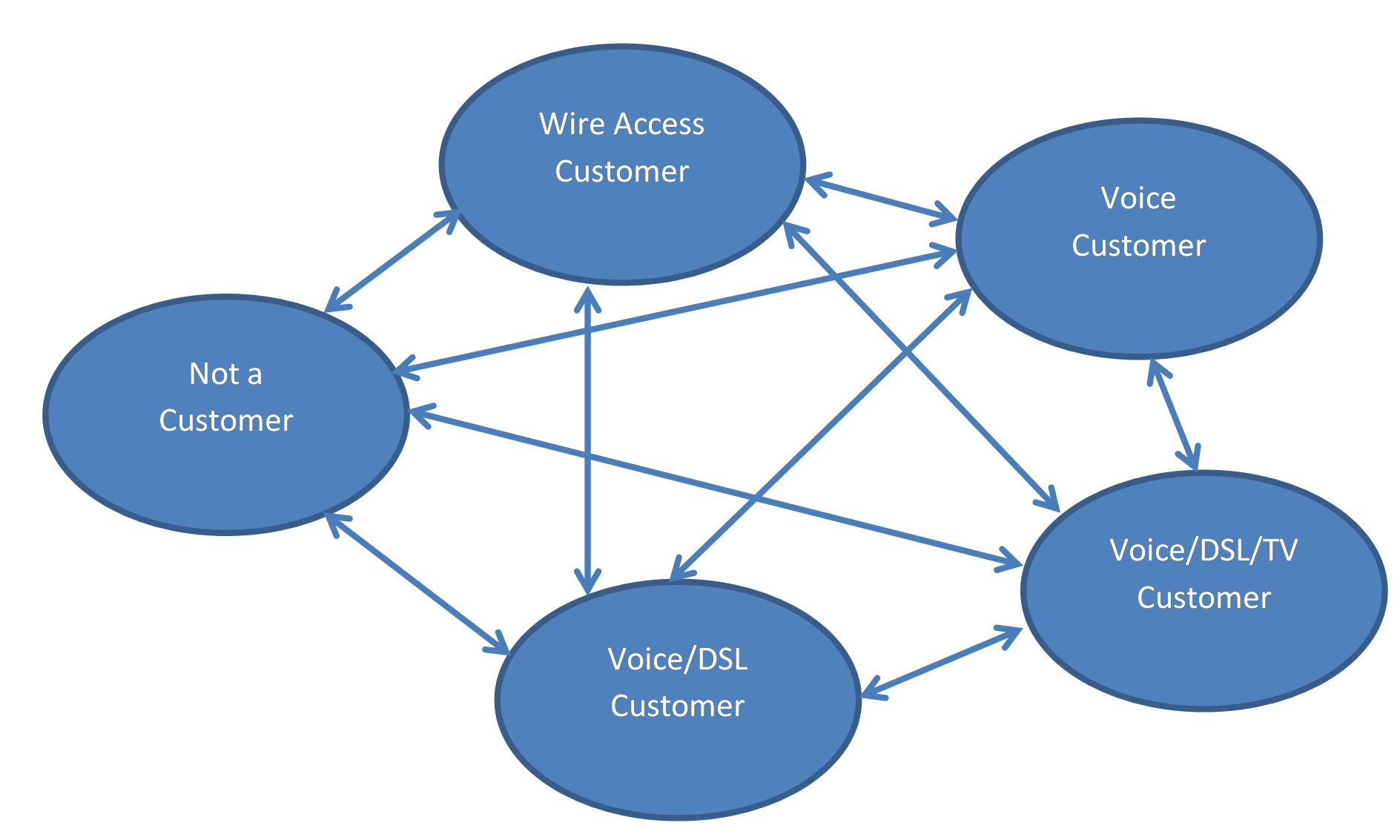
Now for each of these states, we require a state-specific
- prediction model providing each individual’s soujourn time
- prediction model providing each individual’s transition probabilities
- prediction model providing each individual’s revenue
Hence the SMM-based CLV computation for the present example requires a fair number of prediction models. Most of them rely on numerous features which besides socio-demographic data contain the full details of past product usage. This can and does involve data from billions of connections and therefore definitely marks a big data task. Once all parameters for a customer are estimated, his/her CLV can be computed in closed form, based on SMM algebra.
Challenges in the Practical Implementation
However, neither for the customer relationship manager, nor for the data analyst the task is finished once the CLV estimation framework is set up: it needs to be applied in regular intervals (typically monthly or weekly), for being able to track customer movements, changes in customer behavior, et cetera. Completely rebuilding all prediction models would be much too time consuming and fortunately also did not prove to be necessary. The canonical approach is to just keep the current models running in a non-reviewed fashion and have them reproduce their output. While this usually works for short horizons, the models degrade in quality over shorter or longer time spans. This creates the need for an automatic system that produces the necessary output, but also monitors the output quality and sets a red flag if human interaction is required. However, the challenges of building and operating such an automatic system will be discussed in a future blog post on this site.